
Don't jeopardize your RAG - RAG with Question Generation
Are you trying to build your own AI chatbot but finding it giving low quality responses? Did you build a whole vector database, yet find that many questions don’t match to relevant context? Then your Retrieval Augmented Generation (RAG) is in jeopardy, and this blog post is for you.
The Problem
In the game of Jeopardy! one of the rules is that responses must be in the form of a question. For example, a player is given an answer like “King Louis XIV ruled over this European country” and be expected to come up with the question “What is France?”. This is an awkward way of asking about trivia, but it makes the game more challenging due to the extra mental steps.
The problem is that when most people are doing RAG, they are asking their vector database to do extra mental steps. This results in poor quality results. Most knowledge documents are statements of facts, in narrative form. For example, see the wikipedia page for France. In a basic RAG setup, these documents are then divided into smaller chunks. Each chunk is sent through an embedding model, which creates a multi-dimensional vector. The vectors are then stored in a vector database.
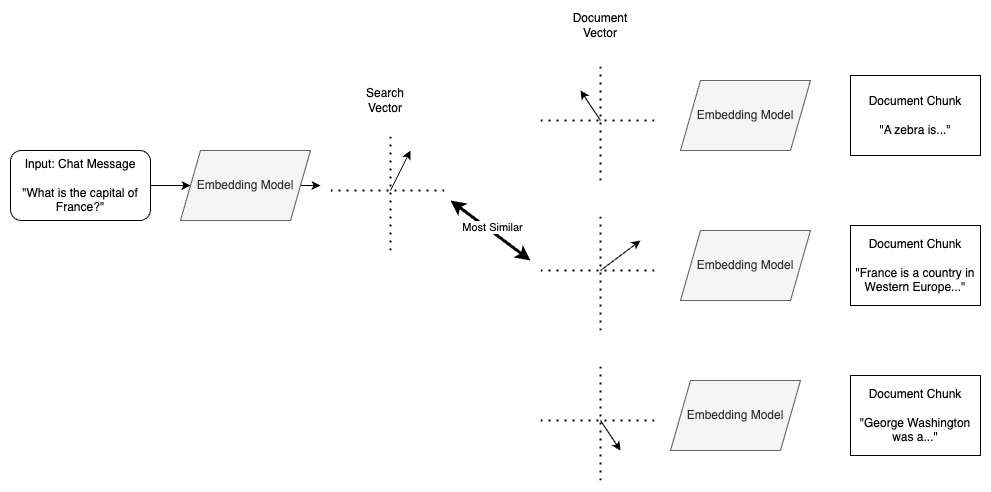
Upon retrieval, the raw chat message is sent through the same embedding model, creating a “search vector”. This is then compared to all of the other vectors currently in the vector database to see which document chunk or chunks are most similar. The retrieved document chunks are then used by a Large Language Model (LLM) to create a more-informed response to the original question.
The problem is that there is a fundamental semantic mismatch between the vectors being compared. We’re trying to compare questions (from the chat message) to answers (from the document chunks). The embedding vector for a question will always be different from the embedding vector for an answer. This leads to unnecessarily poor performance of the RAG process.
Partial Solution: Hypothetical Document Embedding (HyDE)
One way that we can improve performance is Hypothetical Document Embedding (HyDE). This approach uses an LLM to transform the input chat message into answer form, even if it has to hallucinate the answer.
For example, it would turn an input question such as “What is the capital of France?” into a hypothetical answer “The capital of France is New Jersey”.
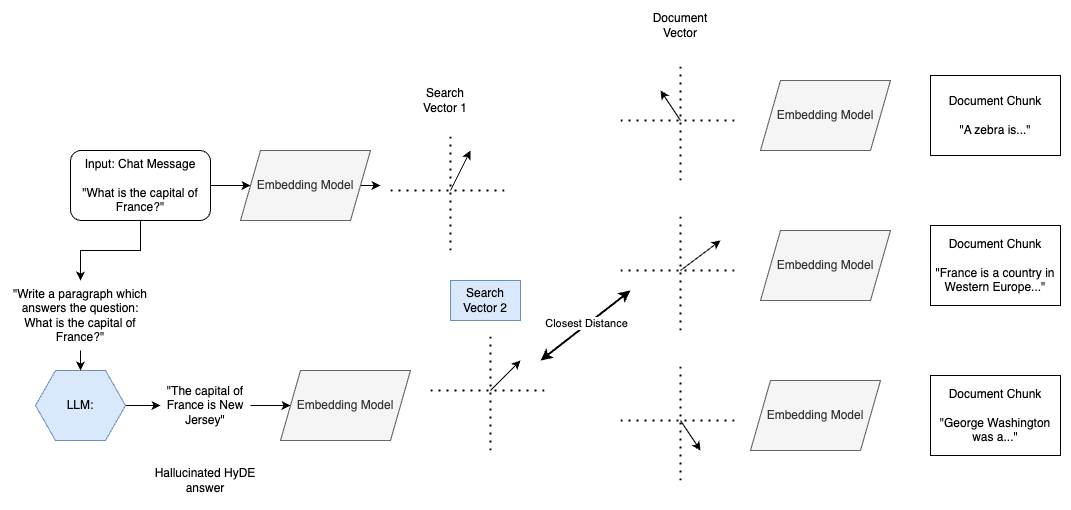
This hypothetical answer is wrong, but it’s embedding vector is likely to more closely match the document chunks. With HyDE, we are matching answers to answers, resulting in more similar embedding vectors. Note that, to get the most out of this approach, it is a good idea to also try to match the original question in addition to the hypothetical answer.
New Solution: RAG with Question Generation
An improved solution is to do pre-processing on the document chunks before they go into the vector database. We can ask an LLM to generate questions which are best answered by the document chunk.
For example, take text from the wikipedia page for France. Then send the LLM a prompt: “Generate a list of standard questions best answered by: {text}” and it generates questions such as: “What is the capital of the country France?”. Use the resulting questions, generate embedding vectors for each, and store them in the vector database, with a reference to the original document text to use as context.

This method uses the vector database to compare questions to questions, resulting in better RAG performance. The vectors for the user’s chat question and the generated questions are much closer, potentially even exactly the same. While this does result in more vectors to search, that leverages the strength of a database, which is to make that search fast and efficient.
In a full implementation, combine all three semantic match techniques:
- original question to document chunk “answer”
- generated hypothetical answer to document chunk answer (HyDE)
- original question to generated question (NEW)
This ensures that we maximize the chances for a better semantic match, resulting in better context being retrieved and better knowledge for our chatbot. We haven’t found any academic papers about this approach, but in our own empirical testing it gives better results.
Next Steps
If you’d like to try this out for yourself, we also made two open source tools which may be of interest.
chatbot-confidential is a fully-local (no data in the cloud, no API calls to the cloud) knowledge chatbot which can run on your own desktop or laptop. It is still in beta, but it uses both of the approaches described in this blog post, and some initial testing has shown this to be promising.
parallel-parrot is a Python package which optimizes parallel calls to the OpenAI Chat API. It can be used to efficiently generate questions from thousands of document chunks at a time, without having to worry about rate limits or throttling of the API.